data150
This project is maintained by Jingwen-Yao94
Jingwen Yao
Word count:1252
Introduction
As the rapid development of the society, transportation has been an indispensable part of human activities. However, some of the developing countries are facing with problems in constructing transportation systems. To improve the systems, intelligent transportation system has been developed and represent the future direction of the transportation system. Also, intelligent transportation systems also start looking at Big Data with great interests because of the success of big data analytics in various field. In this article, I will look at how Support vector machine (SVM) works in process of transportation development and evaluate their values.
Problem statement
Some transportation problems exist that may harm individual people from different perspectives. Congestions on the road may lead to restrictions on car use in some urban areas, which limits people’s choices in transportation. There’s also an increasing accident risks interacting with the congestion, which threatening people’s lives. Also, there can be lack of access to modern world in mountain areas and limited land resources that prevent cities from building new infrastructure such as highways and freeways. Though large percentages of some developing countries’ total expenditures are spent on transportation system, the situation has not been improved for several years. Incomplete ITS theory, insufficient research and the separated resources by industry barriers may be one of the reasons why traffic problems persist.
SVM in traffic incident detection
Support vector machine (SVM) is a popular supervised learning algorithm in machine learning that use labelled data for regression and classification. When people were trying to make precise traffic incident detection, SVM was introduced and applied after artificial neural networks was found to have a defect that limits its wide application. Traffic incidents are defined as nonrecurring events such as accidents, disabled vehicles, temporary maintenance and construction activities, etc. As the rapid development of road infrastructure construction of China, the number of vehicle and highway mileage keep increasing along with frequent traffic incidents. People want to focus on improving the ability of forecasting the development trend of traffic fatality under existing road traffic conditions because if the incident cannot be handled in time, it will increase traffic delay, reduce road capacity, and often cause second traffic accidents. We neither want congestion to reduce the efficiency of the transportation system nor more accidents which threaten personal safety and may even hurt people’s lives. In order to construct a more efficient and safe transportation system, timely detection of incidents is critical.
SVM
SVM is a kind of supervised learning model based on statistical learning theory that is trying to minimize risk and be accurate. It is a fairly mature method in small sample situation and has a better generalization ability to solve machine learning problems in classification and induction. One of the advantages of SVM is that it does not get trapped in a local optimum, which means SVM do not need to perform complex nonlinear optimization and not fall into local optima because of its global optimal characteristics. To further explain that, the corresponding kernel function is defined when solving the nonlinear operation to greatly simplify the calculation. SVM maps the data in the nonlinear low-dimensional space into linear high-dimensional space, and transfers the search for the optimal linear regression hyperplane algorithm into solving convex programming problem under convex constraint, so as to get the global optimal solution. Following are some mathematics equations to represent the function approximately.
Given a set of data points (x1, y1), (x2, y2), …, (xl, yl )(xi∈ X⊆ Rn, yi∈ Y⊆R, l is the total number of training samples) randomly and independently generated from an un- known function, SVM approximates the function using the following form: f(x)=w⋅ϕ(x)+b (1)
In the case of predicting traffic incidents, x is the input that consists of the values of the traffic flow parameters such as volume, speed, occupancy and so on, and y represents the class label of x. In the equation above, ϕ(x) represents the high-dimensional feature spaces which is nonlinearly mapped from the input space x. ω represents the weight vector and b represents the offset value, both of them are estimated by minimizing the regularized risk function:
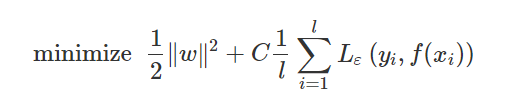 (2)
(2)
The first term ∥w∥^2 is called the regularized term, which is a process of adding information. Minimizing ∥w∥^2 is trying to make the function as flat as possible, thus playing the role of controlling the function capacity. The second term is the empirical error measured by the ε-insensitive loss function:
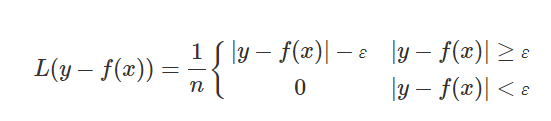 (3)
(3)
This loss function provides the advantage of using sparse data points to represent the designed function. C is referred to as the regularization constant. ε is called the tube size. They are both user-prescribed parameters and determined empirically.
Then, we transform the equation (2) to the primal objective function (4) below to estimate w and b by introducing the positive slack variables ξ(∗)i (∗ denotes variables with and without ∗)
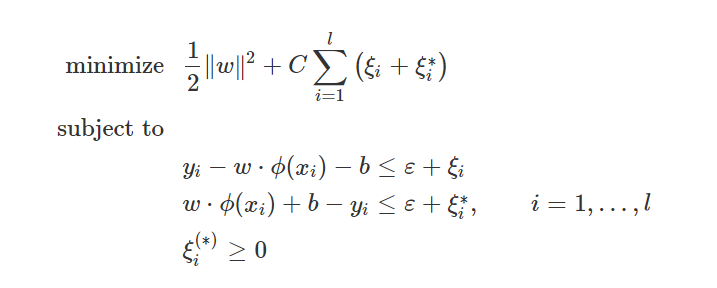 (4)
(4)
where, the Lagrange multiplier ai and ai* are introduced, and the problem is transferred further into a simple optimization problem of the dual problem
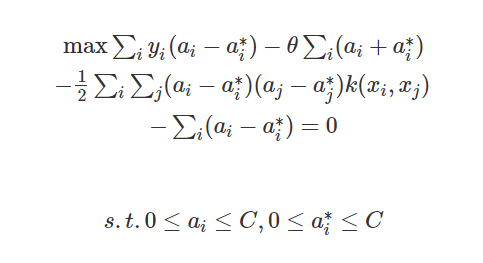 (5)
(5)
Then we could get the final function as follows:
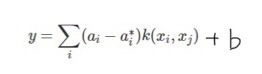 (6)
(6)
K(xi, xj) represents the kernel function, which is equal to the inner product of the two vectors φ(xi) and φ(xi) in the feature spaces. The kernel function is set to avoid operating the complex operation caused by φ(xi) and φ(xj) that it can deal with feature spaces of arbitrary dimensionality without having to compute the map ϕ(x) explicitly. It is the key to the nonlinear SVM problem, which can map low-dimensional data to higher dimensions, and the data can be linearly separable. To conclude the principle of SVM, we need Lagrange multiplier ai and ai*, input vector xi and xj with the kernel function and the offset value b to get the result.
The prediction model of traffic fatalities
In order to improve urban transportation, we are trying focus in achieving a comprehensive assessment of traffic accidents. There are three principles that the choice of relevant indicators should follow– representation, testability, and comparability. When thinking of the construction the traffic system, people, vehicle and road are three basic factors that need to be considered. And we know that traffic accidents often happen randomly because of a variety of quantitative factors and qualitative factors. In the literature on traffic accident prediction, highway mileage, vehicle number, lane width, average daily flow, and population are selected as impact factors. The combination of many factors including person, vehicle and road, highway mileage, vehicle number, population size, led to the occurrence of traffic accidents. For the output variable, we could compare the traffic fatality with the known real data for accuracy since traffic fatality is too serious to be neglected in real life.
According to previous research, the current widely used indicators of traffic accidents are the number of traffic fatalities, the number of injuries, the number of road traffic accidents and economic losses. Here we select the most comparable traffic accident deaths as predictor index because there is no uniform statement about the definition of injury. Therefore, we get the traffic accident prediction model shown below.
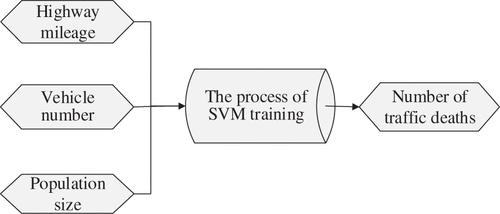
Conclusion
As mentioned above, the model is using traffic accident deaths as predictor index partially because the road traffic accident statistics about road accidents has not been completed yet. The index still needs to be further modified in order to better answer my question, which is how to solve current transport problems and improve urban transportation system. The index can include the degree of traffic jam and economic losses caused by the incidents, etc.
Reference: Gu, Xiaoning, Li, Ting, Wang, Yonghui, Zhang, Liu, Wang, Yitian, and Yao, Jinbao. “Traffic Fatalities Prediction Using Support Vector Machine with Hybrid Particle Swarm Optimization.” Journal of Algorithms & Computational Technology 12.1 (2018): 20-29. Web.
Cao, L.J, and Tay, F.E.H. “Support Vector Machine with Adaptive Parameters in Financial Time Series Forecasting.” IEEE Transactions on Neural Networks 14.6 (2003): 1506-518. Web.